![]()
Understanding:
• Chi-squared tests are used to determine whether the difference between an observed and expected frequency
distribution is statistically significant
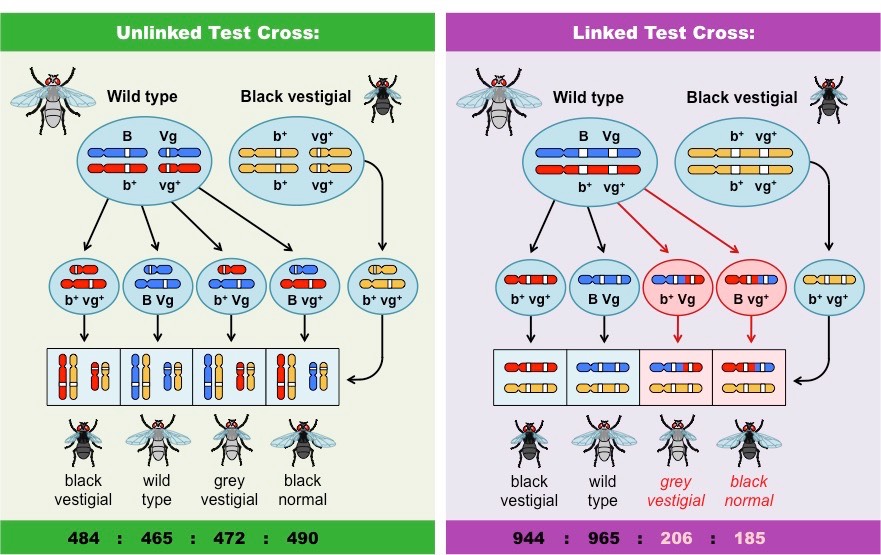
It is possible to infer whether two genes are linked or unlinked by looking at the frequency distribution of potential phenotypes
Offspring with unlinked genes have an equal possibility of inheriting any potential phenotypic combination
- This is due to the random segregation of alleles via independent assortment
Offspring with linked genes will only express the phenotypic combinations present in either parent unless crossing over occurs
- Consequently, the ‘unlinked’ recombinant phenotypes occur less frequently than the ‘linked’ parental phenotypes
Frequency Distribution of Unlinked and Linked Genes
Chi-Squared Tests
Chi-squared tests are a statistical measure that are used to determine whether the difference between an observed and expected frequency distribution is statistically significant
If observed frequencies do not conform to those expected for an unlinked dihybrid cross, this suggests that either:
- Genes are linked and hence not independently assorted
- The inheritance of the traits are not random, but are potentially being affected by natural selection
![]()
Skill:
• Use of a chi-squared test on data from dihybrid crosses
A chi-squared test can be applied to data generated from a dihybrid cross to determine if there is a statistical correlation between observed and expected frequencies
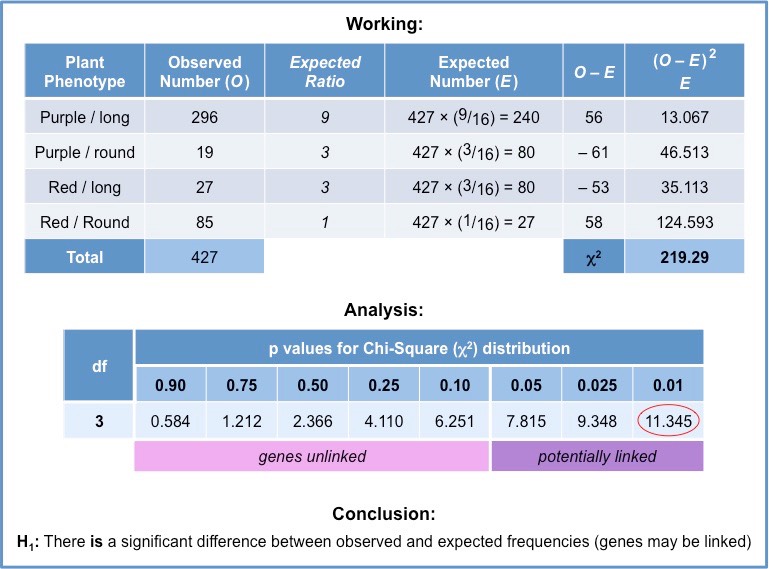
A chi-squared test can be completed by following five simple steps:
- Identify hypotheses (null versus alternative)
- Construct a table of frequencies (observed versus expected)
- Apply the chi-squared formula
- Determine the degree of freedom (df)
- Identify the p value (should be <0.05)
Example of Chi-Squared Test Application
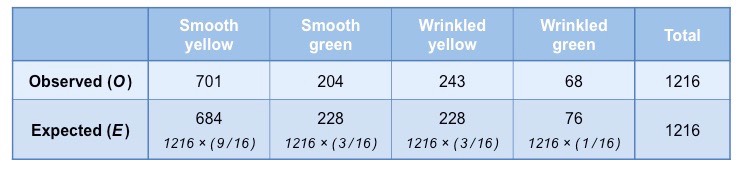
The trait for smooth peas (R) is dominant over wrinkled peas (r) and yellow pea colour (Y) is dominant to green (y)
A dihybrid cross between two heterozygous pea plants is performed (RrYy × RrYy)
The following phenotypic frequencies are observed:
- 701 smooth yellow peas ; 204 smooth green peas ; 243 wrinkled yellow peas ; 68 wrinkled green peas

Step 1: Identify hypotheses
A chi-squared test seeks to distinguish between two distinct possibilities and hence requires two contrasting hypotheses:
- Null hypothesis (H0): There is no significant difference between observed and expected frequencies (i.e. genes are unlinked)
- Alternative hypothesis (H1): There is a significant difference between observed and expected frequencies (i.e. genes are linked)
Step 2: Construct a table of frequencies
A table must be constructed that compares observed and expected frequencies for each possible phenotype
- Expected frequencies are calculated by first determining the expected ratios and then multiplying against the observed total
Step 3: Apply the chi-squared formula
The formula used to calculate a statistical value for the chi-squared test is as follows:
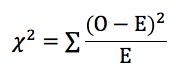
Where: ∑ = Sum ; O = Observed frequency ; E = Expected frequency
These calculations can be broken down for each phenotype and added to the table to make the final summation easier
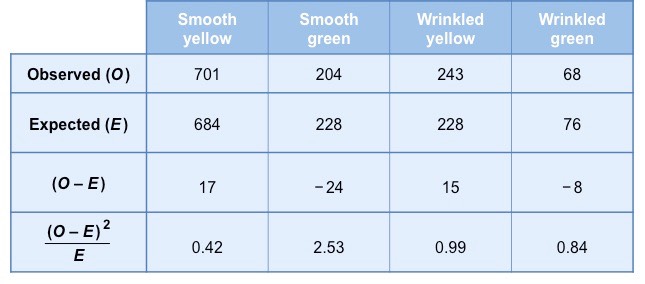
Based on these results the statistical value calculated by the chi-squared test is as follows:
- 𝝌2 = (0.42 + 2.53 + 0.99 + 0.84) = 4.76
Step 4: Determine the degree of freedom (df)
In order to determine if the chi-squared value is statistically significant a degree of freedom must first be identified
- The degree of freedom is a mathematical restriction that designates what range of values fall within each significance level
The degree of freedom is calculated from the table of frequencies according to the following formula:
df = (m – 1) (n – 1)
Where: m = number of rows ; n = number of columns
For all dihybrid crosses, the degree of freedom should be: (number of phenotypes – 1)
- In this particular instance, the degree of freedom is 3
Step 5: Identify the p value
The final step is to apply the value generated to a chi-squared distribution table to determine if results are statistically significant
- A value is considered significant if there is less than a 5% probability (p < 0.05) the results are attributable to chance
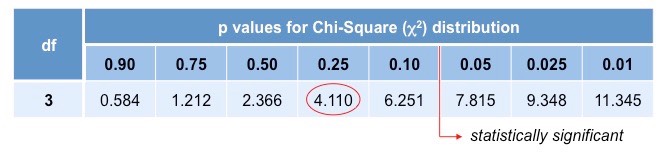
When df = 3, a value of greater than 7.815 is required for results to be considered statistically significant (p < 0.05)
- A value of 4.76 lies between p values of 0.25 and 0.1, meaning there is a 10 – 25% probability results are caused by chance
- Hence, the difference between observed and expected frequencies are not statistically significant
As results are not statistically significant, the alternative hypothesis is rejected and the null hypothesis accepted:
- Null hypothesis (H0): There is no significant difference between observed and expected frequencies (genes are unlinked)
Practice Question
 In sweet pea plants, the trait for purple flowers (P) is dominant to the trait for red flowers (p).
In sweet pea plants, the trait for purple flowers (P) is dominant to the trait for red flowers (p).